
Omezený přístup k velkým datům (big data) vytváří digitální propast mezi velkými společnostmi a širší akademickou komunitou, tvrdí Kate Metzler ze SAGE Publishing. Ve svém textu pro LSE Impact Blog zmiňuje Clivea Humbyho, matematika a architekta stojícího za projektem Tesco Club Card, který se už v roce 2006 nechává slyšet, že „data jsou nová ropa“. Srovnáním odkazuje k hodnotě, která je získávána čištěním základní suroviny v případě ropy nebo analýzou v případě dat. Data jsou však produkována rychleji, než se je daří zpracovávat a analyzovat. Vždyť už v roce 2013 bylo možné říct, že 90 % dat bylo vyprodukováno v předchozích dvou letech. Metzler cituje hlavního ekonoma společnosti Google: „Před miliardou hodin se objevil druh homo sapiens. Před miliardou minut začalo křesťanství. Před miliardou sekund bylo vytvořeno IBM PC. Před miliardou vyhledávání na Googlu… to bylo tohle ráno.“
Žijeme v éře revoluce velkých dat, která – i za přispění umělé inteligence – mění jednotlivá vědecká pole. Dávají nám příslib, že dokážeme lépe zodpovědět fundamentální otázky o jednotlivcích i skupinách. Jenže kdo získává přístup k datům, která produkujeme prostřednictvím stále propojenějších a digitálnějších životů? A pro jaký účel?
Již v roce 2012 nabídly dvě výzkumnice Danah Boyd a Kate Crawford kritický pohled na velká data a přišly s myšlenkou rozdělení na „big data rich“ a „big data poor“. Jak jsem rovněž ilustroval ve starším článku Jak statistika ztratila svoji moc a co přichází po ní, jsou to hlavně velké společnosti, které dnes mají přístup k rozsáhlým sociálním transakčním datasetům. Vědecká obec pak tento přístup postrádá: buď tyto velké společnosti odmítají přístup ke svým datům, nebo je příliš nákladné se k nim dostat.
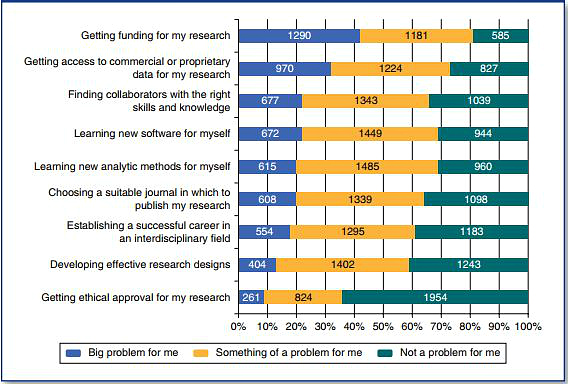
Metzer provedla výzkum více než 9 tisíc sociálních vědců, aby zjistila, jakým čelí překážkám při nakládání s velkými daty či přístupu k nim. Jak ukazuje následující graf, problémem jsou zejména finance, přístup ke komerčním datům, ale také odbornost výzkumníků.
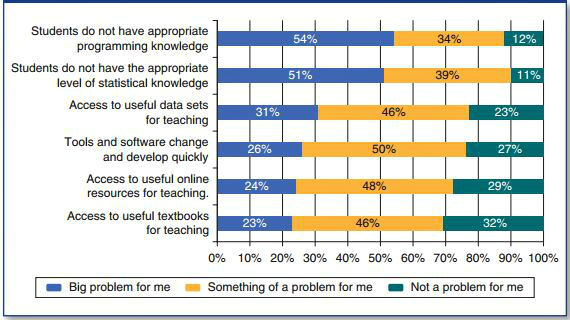
Problémem je tedy také úroveň schopností pro nakládání s kvantitativními daty a schopností v programování (více v tomto grafu). Existují sice názory, že by sociální vědci neměli usilovat o provádění výzkumu, který si mohou společnosti jako Twitter nebo Facebook provádět samy, podle Metzer je však více důvodů, proč je to problematické. V první řadě z důvodu, že replikace je motorem vědy a nereprodukovatelný výzkum zpomaluje vývoj. Pokud jsou to jen privilegovaní výzkumníci velkých firem, kteří mohou přistupovat k velkým datasetům a analyzovat je, ti bez přístupu nemohou reprodukovat ani evaluovat jejich metodologické postupy. Zároveň existují odlišné motivace sociálních vědců od těch, kteří jsou zaměstnáni velkými firmami. Výzkum velkých dat prováděný velkými společnostmi je jistě užitečný při dosahování jednoho cíle, a sice prodat více zboží či služeb, zatímco sociální vědci mohou svým výzkumem přispívat k všeobecnému vědění, s cílem lépe porozumět sociální realitě. Boyd a Crawford se ptají, zdali může výzkum velkých firem přispět k veřejnému blahu, vytvořit nové, užitečné nástroje pro výzkum, nebo spíš přijde s novými formami invazivního marketingu. Současně se ukazuje, že vstupuje-li do říše velkých dat silný státní aparát, může dojít k nové, historicky nevídané úrovni represe a kontroly.
Sabina Leonelli z University of Exeter artikuluje strach, který vyvolává vývoj digitálních technologií a umělé inteligence a který může vést k rozšíření existujících nerovností a sociálního rozdělení (vzpomeňme si například na případ genderové předpojatosti umělé inteligence, která měla pro své učení k dispozici data bez korekcí a zásahů člověka). Podle ní jsou data nejcennější, když mohou cirkulovat a být interpretována ve vztahu k odlišným otázkám a problémům. V tomto smyslu je rozkvět velkých dat a s nimi spojené infrastruktury a expertízy propojen s rozkvětem otevřené vědy, tedy hnutí, které využívá digitální platformy a komunikační technologie k revoluci v tom, jak se globálně vytváří a jak cirkuluje vědění. Propojení velkých a otevřených dat propojuje oblasti tak odlišné, jako je umělá inteligence, zemědělství a veřejné zdraví, a je příslibem transformace lidských možností čelit globálním výzvám. Zároveň má však potenciál zásadním způsobem podrýt legitimitu, kredibilitu a důvěryhodnost vědecké expertízy a rozšířit již tak hlubokou propast mezi těmi, kteří benefitují z digitálních technologií, a těmi, kteří ztrácí.
Leonelli se ve svém výzkumu zaměřila na to, jak jsou data rozesetá a využívaná napříč širokou škálou kontextů, v rámci vědy i mimo ni a na různých místech, ať už v bohatých nebo chudých zemích. V rámci svého projektu přichází se třemi hlavními obavami, které jsou spojené se současnou organizací velkých dat:
- Neudržitelnost povahy krajiny digitálních dat a urgentní potřeba najít byznysové modely, které mohou podporovat uložení dat, jejich sdílení a analýzu. Otevřená věda není rychlá, ani levná. Vyžaduje digitální a materiální infrastruktury, které jsou efektivní jen pokud jsou efektivně udržovány a pravidelně updatovány. Kdo by měl tyto náklady nést? Jak by měla tato infrastruktura být koordinována lokálně a mezinárodně?
- Kvalita a kredibilita samotných dat a procesů používaných k transformaci těchto dat ve vědění. V éře fake news je důležitější než kdy jindy poskytovat evidenci pro vědecká tvrzení, nicméně většina datových kolekcí a online úložišť postrádá efektivní systémy kontroly kvality a hodnocení. Zároveň panují pochyby o algoritmech, které jsou používány pro datové analýzy. Globální rozpětí a množství rozmístění vzájemně propojených databází činí tyto systémy neprůhlednými a je obtížné zjistit, jak ovlivňují interpretaci dat.
- Míra, do jaké velká a otevřená data posilují existující sociální rozdíly, například preference datových zdrojů, které reprezentují pouze privilegované jednotlivce a komunity. Drtivá většina velkých výzkumných databází nabízí „tvárná“ data, produkovaná bohatými, anglicky hovořícími skupinami; naopak jen málo jich reprezentuje méně viditelné a zranitelnější skupiny.
Podle Leonelli je možné tyto výzvy překonat, vyžaduje to však urgentní jednání. Prioritou je podpora spravedlnosti v manipulaci s daty, například prostřednictvím identifikace výjimek a nerovností zabudovaných do datových toků, investice do odpovídající datové expertízy a vývoj inteligentních a etických strategií pro sdílení dat a vývoj algoritmů. Dále výzkumnice navrhuje podporu vývoje mechanismů k propagaci kvality a důvěryhodnosti datových zdrojů a analytických nástrojů, udržitelné datové infrastruktury (zdroje interoperabilní, dlouhodobé, mezinárodně koordinované a veřejně odpovědné) či kreativních řešení globálních výzev v dialogu s relevantními publiky.
Jak se ukazuje, v globálním světě si nevystačíme pouze s lokálními daty a s národními úrovněmi datových úložišť. Podobně, jako není možné klást vědě hranice a uzavírat ji do lokálních rámců, není to možné ani v případě velkých, globálních dat. Jenže dokáže někdo přistoupit k takovým krokům, že se data soukromých společností, které o nás denně sbírají miliardy drobných údajů, stanou veřejnými? A v případě, že budou tato data zpřístupněna, kdo dokáže zaručit jejich úplnost a vyloučit jejich zaujatost?




{kind=link}